The Policy Change Index for Outbreak (PCI-Outbreak) measures the
severity of an epidemic outbreak in China, such as the coronavirus
disease 2019 (COVID-19), using the 2003 severe acute respiratory
syndrome (SARS) as the benchmark. The higher the indicator, the larger
the scale of the outbreak.
Figure: PCI-Outbreak for COVID-19 and official statistics in
China (Jan 21 to Sep 15, 2020)
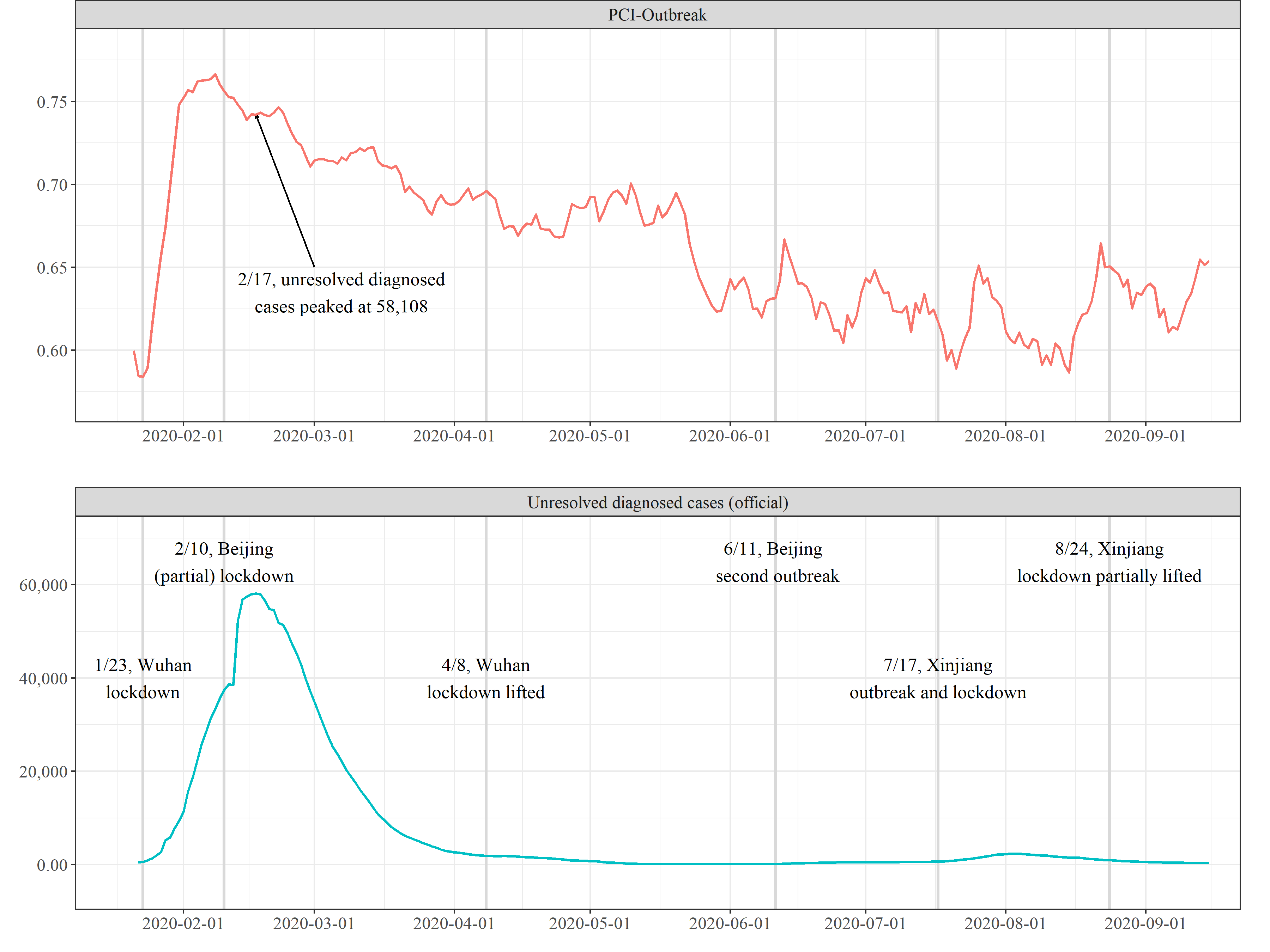
The figure above plots the PCI-Outbreak for COVID-19 in China, in
comparison to the number of unresolved diagnosed cases officially
confirmed by the Chinese government.
Background
How severe was COVID-19 in China, really? It is widely suspected that
the country’s official numbers of diagnosed cases understate the extent
of the outbreak, and even the official statistics themselves are
incoherent. On February 13, 2020, the Chinese authorities confirmed more
than 15,000 new cases nationwide—40 times the previous day’s
number—because of a change in counting criteria. Just two months after
that, they revised the death toll for the city of Wuhan, the epicenter,
upward by 50 percent, citing unspecified omissions.
The PCI-Outbreak uses a deep learning method to measure the severity
of COVID-19 in China, not through the Chinese government’s official
numbers but through how state-controlled media talked about the
outbreak. The algorithm is trained on SARS-episode articles in the
People’s Daily, the official newspaper of the Communist Party
of China, to understand the tone and tenor of the SARS-episode narrative
as the epidemic cycle evolved. The algorithm then assesses future
outbreaks’ severity against the SARS benchmark.
Methodology
The PCI-Outbreak is built on the idea that words can speak louder
than (some) numbers. While it may be simple to release false statistics,
it is more difficult to conceal the truth when the government has to
address a crisis, such as a severe infectious disease, at length in the
media. Take the beginning of COVID-19 for example: When the Chinese
government announced a lockdown of Wuhan, a city with a population of 11
million, and its neighboring cities and discussed the necessity of doing
so in state media, the Chinese authorities had confirmed a total of
fewer than 600 cases of the novel coronavirus across the country.
Therefore, changes in words during the outbreak may provide us with a
clearer picture of the severity than official numbers do.
To detect how the narrative evolves, we build a deep learning
algorithm to “read” People’s Daily articles published during
the SARS episode. Using the Bidirectional Encoder Representations from
Transformers (BERT), a natural language model developed by Google, the
PCI-Outbreak algorithm takes a two-step process:
It first learns to classify whether a piece of text is related to
the SARS outbreak.
Conditionally on the text’s being SARS-related, the algorithm
then learns to infer when in the SARS news cycle the text was
published.
Because the 2003 SARS outbreak in China went through a typical
epidemic cycle — starting in November 2002, peaking in May 2003, and
being contained in July 2003 — the timing of publication is effectively
a proxy for the spread of the disease.
Once the algorithm is trained, we deploy the program to People’s
Daily articles during the COVID-19 episode. Because the algorithm
has learned from the past episode, it would make two predictions on the
current data: whether each new piece of text is related to an epidemic
and, if so, when the text would have been published in the SARS
timeline. The second prediction will likely be factually incorrect —
classified as from 2003 but actually from 2020. But this error is
exactly what we aim for: Each date in the COVID-19 outbreak timeline is
cast back to the SARS timeline and, therefore, results in a metric of
severity in the SARS epidemic cycle and how the crisis is truly
perceived by the Chinese authorities.
Main Results
The figure shown above contrasts the severity measured by the
PCI-Outbreak and China’s official count of diagnosed cases. We make
three observations:
The Chinese government’s official numbers of diagnosed cases are
consistent with the PCI-Outbreak measure until the peak of the COVID-19
outbreak in China—both measures indicate that cases peaked in February
2020.
After the peak, the official numbers and the PCI-Outbreak
diverge. The PCI-Outbreak trends downward, but at a much slower rate
than the official numbers, suggesting that the Chinese government may
have exaggerated the speed at which the virus was contained
The PCI-Outbreak stays elevated from June to September, while the
official numbers have stayed low since April. This discrepancy suggests
that recent outbreaks in Beijing and Xinjiang may have been more severe
than what the official numbers indicate.
Note: More details of the project can be found in our research
paper. We have also released the source code of the project on
GitHub.